





开场0:00
哈喽大家好 , 我是明昊 。 呃 , 我翻了一下我自己小宇宙的后台 , 距离我上一次更新 PPT 的 "Solo 的播客 " 应该刚过去半个多月的时间 。
我上一期关于 DeepSeek 的播客的内容 ,其实是讲 DeepSeek,以及对于 25 年所谓 "Agent 年 " 的一些预期的 。 可是现在回头去看 , 你会发现 ,其实我对自己的评判在那一期里面关于 Agent 的讲述是有一些空的 。
我相当于在那个时间点 ,是针对那一章节的内容做了一定的 " 讨巧式 " 的内容处理 。 所以那一段内容回头来看 ,其实没有太多的观点 , 更像是已有信息的排列组合 。
为什么呢 ? 其实说实话 ,在那个时间点 , 无论是我还是业界 , 本质上来讲对 Agent 这件事情没有那么明确的认知 。
那直接我们引出今天的话题 : 为什么会做这一期内容 ? 其实在这个时间点 ,在过去的可能一周左右时间 , 呃 , 整个 AI 行业都在谈论 Manus。
我作为业界的观察者 , 对这件事情也有一些更深的认知跟理解 , 所以有了今天这样一期播客的内容 。
嗯 ,2025 年刚刚过去三个半月 , 两个半月的时间 , 我已经做了 3 个超长的 PPT 了 。 对 , 这是第三个 。
我们今天的内容叫 《Manus 没有秘密 》。 本来我还加了一个副标题 , 叫 《2025 年会是 AI Agent 年吗 ?》 是一个问号 。 可是我做了之后发现 ,其实这个问题可能不需要再问了 。
核心叙事1:50
我们正式进入今天的内容 。 呃 ,《Manus 没有秘密 》 其实是 5 章的内容 ,有大概 70 页的 PPT。 如果大家需要 ,也可以去手动下我的 PPT 文档 。
呃 ,5 章内容的标题分别是 : 核心叙事 、 定义 Agent、 实现原理 、Manus 的使用体验 ,以及最后的一些暴论输出 。
我很庆幸的是说 ,其实你对一件事情有比较多的了解的时候 , 才会有比较多的暴论 ; 当你没有那么了解的时候 , 更多做的是信息的罗列 。
我们正式进入今天的内容 。
也就是差不多一个月多之前 , 我做了那个上一次的 PPT 内容 : 从 DeepSeek 爆火看 25 年的 AI 行业发展 、 讲 DeepSeek 爆火的整个过程 、 过去两年的 AI 行业的叙事 ( 包括新叙事的可能性 ), 以及最后一章所谓 Agent。
正如我刚才前面所说 ,其实这 4 章内容中的前 3 章我觉得都是老东西 。 第 4 章是本来应该有些观点跟 、 呃 , 出彩的地方 ,但其实受限于我对这个行业的认知跟理解没有到 , 所以我会觉得当时做的这个关于 DeepSeek 以及 AI Agent 内容的第 4 章并不那么理想 。
那就很幸运的是 , 我们聊到今天的话题 。 那同样的是引用之前那个话题 : 如果当期的那一期播客如果大家回去翻的话 , 我在那一期播客的 PPT 里就有讲过 。
如果那个大概 70 页的 PPT 只用 1 页做总结的话 , 就是 OpenAI 定义的 L1 到 L5, 然后我们现在在 L2 到 L3 之间 , 对吧 ?
那详细点来说 ,L1 就是 Chatbot,以 ChatGPT 为代表的我们今天能够用到的很多产品都是 L1。L2 是推理模型 , 嗯 ,OpenAI 的 O1、DeepSeek 的 R1,以及 DeepSeek 的 R1 之后一系列的投入供应厂商所有人发布的推理模型 , 这是 L2。L3 就是我们今天讨论最直接的话题 , 叫 Agent。
嗯 ,在上一次的 PPT 里我也讲过 ,Agent 这概念被无限地泛化了 。 那今天很好 ,有人把它定义得更清楚了 。
所以如果今天还依然只有 1 页 PPT, 我依然可以用这 1 页 PPT 来总结所有的内容 。 那我们掰开了 、 揉碎了来聊一聊 L1 到 L3。其实之前的时候 ,在上一次 PPT 整理的过程中, 我并没有那么详细地解释 , 我列了一些问题 。
比如说 , 我们从 L1 的 Chatbot 再往前推 ,在 1415 年, 甚至再晚一点点兴起的那一波 AI 1.0 年代的模型公司 ,其实今天也还在 。
就是所谓的中国的 , 比如说当年的 AI 四小龙 。 那我们回头去想 , 那个年代的 AI 1.0 跟大模型年代的 AI, 最大的区别是什么 ?
那我们当时是怎么从原来那个样子走到大模型的 , 就是走到 GPT 的 。 然后再去想 ,22 年底的时候 , 呃 ,其实 22 年中 GPT 就发了 3, 然后发了 3.5, 到 22 年 11 月 30 号 ,ChatGPT 发布 , 才被定义成这个行业到了一个节点 。
那我想问的是 ,ChatGPT 对于 GPT 3.5 的意义是什么 ?
然后这是 L1。 那到 L2 的时候 , 从 OpenAI 的 O1 9 月份 、2023 年的 9 月份发布 , 到 DeepSeek 的 R1 是 2025 年的 1 月发布 , 我们又是怎么走到 L2 的 ?
还有一点 , 就是为什么每一次的大模型的重大更新 , 都看上去有一波应用公司死掉
。 这个问题再延展 , 变成了模型跟产品这两件事情到底是统一的 , 还是分开的 ? 有可能会说模型即产品 ,也有可能会说模型跟产品应该分开 。
那是不是这件事情的问题 ,在不同的阶段是有不同的答案的 ? 这是一些问题 。 我的核心思想是什么呢 ?
其实挺 、 挺简单的 。 就是刚才我问了 , 我们从之前的 1.0 年代到了大模型年代 , 然后从基础大模型到推理模型 , 到今天我们去探讨 Agent。
呃 , 第一个关键词我写的叫 " 通用 "。 也就是说 , 我们这一波大模型叫 " 通用大模型 ",L1 就是通用的 。
到了推理模型的时候 , 我们也开始在做叫 " 通用推理模型 "。 因为我没有 、 我们几乎没有做一个什么垂直行业的推理模型 , 对吧 ?
推理模型出来就是通用的 。 那这个逻辑再往下推 , 如果 L3 是 Agent, 那是不是应该也是一个通用 Agent 呢 ?
通用 。 第二个关键词叫 " 技术实现 "。 就刚才问 , 我们怎么一步步走过来的 ? 从之前的 AI 1.0 到大模型 , 我们之前用过一个关键词叫 " 大力出奇迹 ", 对吧 ?
预训练 。 到 L2 的时候 , 强化学习变得重要了 。 那在 L3 呢 ? 或者说从 L1 到 L2, 嗯 ,AI 1.0 叫 L0 吧 ,L0 到 L1 到 L2 的过程中, 你会发现 , 一直大家遵循的一个观点是说 , 尽量少的控制 , 给更多的数据 、 更强化学习的方式 , 让模型本身自己学习 。
这是技术实现的过程 。 再第三个关键词叫 " 用户感知 "。 也就是说 , 对于一个用户而言 ,他怎么去感知技术的变化 ?
大家经常会说所谓的 "Aha moment", 就是用户哇哦 , 会像看到魔法一样 。 那种时刻是对一个普通用户而言 ,是不是那么难理解的一件事情 。
然后你会发现 , 从
L1 到 L2 到 L3 的过程中, 都在经历从简单变复杂 、 再变简单 、 再变复杂的过程 。 所以如果总结来看 L1 到 L3 的整个过程 , 我会觉得有几个关键词 : 通用 、 技术实现 、 跟用户感知 。
听起来有点神棍 , 对吧 ? 我们一个一个看 。 先看通用 。 我用了一张创新工厂 01 万物刚刚成立的时候 , 开普老师在一次发布会上的 PPT 的一页 ,他讲的是 AI 2.0, 就是大模型克服了 AI 1.0 单领域跟多模型的限制 。
也就是说 ,在之前 AI 1.0 年代 , 我们是用单一的数据集 , 然后在单一的场景下训练固定的模型 。 到了大模型年代 , 变成通用的 , 对吧 ?
这个 、 这个是在大模型年代就出现了 。 然后那我们是怎么到的 L2? 这个如果大家有兴趣 , 可以去详细地去回看我之前讲 DeepSeek 那期的播客里 。
就是之前 O1 发布之后, 呃 , 世界上的主流模型厂商都希望复现 O1 的推理的模型 , 所以用了两个路径或者两个技术方案 。
一个叫 COT, 就是思维链 , 对吧 ? 就大家会认为 , 呃 ,因为今天如果你用 DeepSeek 的话 , 你已经很了解思维链是什么了 。
但在那个时间点 , 大家会认为 , 让大模型以一步一步的方式去思考问题 , 这个叫思维链 。 那思维链出现之后, 就变成一个 , 呃 , 训练的过程当中, 我们是针对这个链条的每一个环节做激励 , 还是针对结果来做激励 ?
所以当时有了一种路线方案 ,是针对每一个过程 , 就是 PRM, 对吧 ? 然后呢 ,但是最后的结果告诉大家 , 无论是最早复现出来的 , 呃 ,Kimi 的 O1 还是 DeepSeek 的 R1, 我们去看他的开源的文章 , 跟一些他们的员工的社交媒体的发布 , 最后证明是完全只依靠对结果的强化学习 , 我们走到了 L2, 对吧 ?
我们不需要在过程中对模型本身做更多的限制 , 就跟当年 AlphaGo 出现 AlphaZero 一样 。 就是不需要跟人类去学习奇谱 , 我们就可以得到一个更强的 Alpha 这个 Zero 的围棋模型 。
它摆脱了人类的经验 , 对吧 ? 那 DeepSeek 也一样 , 对吧 ?DeepSeek 的基础模型叫 V3, 呃 , 基于 V3 的模型能力做强化学习 , 仅仅针对 , 呃 , 模型本身的结果做奖励 , 就出现了 R1、Zero, 就跟 AlphaZero 一样 。
这是我们走到 L2 的整个过程 , 对吧 ? 然后, 呃 , 从 R1、Zero 再经过一点点的预训练 , 跟简单的基础的信息的 , 呃 , 增加跟数据的调整 , 我们出现了今天我们在用到的 R1,并且 R1、DeepSeek R1 把它这个训练的方案跟方式 , 同时复现在了 Llama 跟 Chainway 上 ,也对那几个模型提升了效率 。
这是整个我们走到 L2 的过程 。 那你回看这样一个过程来说 , 你会发现 , 这是一个纯技术路线的模型层的知识 。
那在用户层是什么呢 ? 我一个说法叫 " 用户需要 magic", 就跟 Aha moment 一样 。Aha moment 是什么 ? 就是用户作为一个非技术人员 , 非常明晰地看见了 。
看见是非常重要的 。 我们回头来看 L1 的年代 ,ChatGPT 的发布 , 作为用户来讲 ,他看见了什么 ? 说得赤裸裸一点 ,他看见了机器在吐字 , 就那么简单 , 对吧 ?
那 L2 的时代 , 就是 O1 或者 DeepSeek R1 的时候 , 用户看见了什么 ? 用户看见了模型在推理 。
那同样这个逻辑往下推 ,L3 如果是 Agent, 或者说那个 Aha moment 出现在了 Agent 这个板块里 , 那也应该是一个用户看见了什么东西 , 对吧 ?
用户需要 magic。 然后再说刚才我们提到一个关键词叫 " 简单复杂 ", 简单 、 一次重复的过程 。 我们看 L1 的年代 ,ChatGPT 刚发的时候 , 所有人都说哇 , 我们只需要自然语言就可以跟大模型交互了 。
但你发现 , 需要出现非常复杂的提示词工程 , 对吧 ? 你需要描述非常多 , 甚至有严格的格式去给模型做刺激 , 它才会给你好的答案 。
然后这是 L1。 那为了到 L2 的时候 , 我们刚才讲了 , 前面又出现了思维链 , 对吧 ? 我希望让模型一步一步思考 。
然后 L2 真的实现的时候 , 你会发现 , 我们现在在用 , 比如 DeepSeek R1 各种各样的推理模型的时候 , 感觉那个提示词工程也不太需要 , 对吧 ?
大模型自己可能会理解了 。 但是训练 L2 的过程 ,其实是一个大家去跑了一些弯路 , 对吧 ? 有很多公司 、 很多模型厂商用了过程激烈的方式 。
然后现在我们要去 L3 了 , 要做 Agent 了 。 你会发现很多厂商在尝试用叫 workflow、 工作流的方式来去定义模型的执行 。
那如果依然延续这个逻辑来讲 , 从简单到复杂 , 再到简单 , 再到复杂 , 再到简单 , 那 L3 是不是应该也不需要 workflow,而且也不应该限定场景 ?
因为你会发现 , 过去这几次的技术更迭 , 从技术实现的角度来看 , 我们的这种路径依赖 , 往往会把我们引到一些弯路上, 最后成的都不是这些弯路 。
总结一下, 第一章掰开了 、 揉碎了讲 L1 到 L3。 第一个关键词叫 " 通用 "。 不是垂类 ,不限定具体场景 ,不设置边界 , 当然这会非常的难 , 且初期的实现一定是不完美的 。
通用 。 第二 , 要让大模型自己来 ,不要干预 ,不要加添加条件 , 更少的限制 , 更好的激励 。 当然 , 对于在做相关工作的公司而言 , 比较考验他们的是成本跟结果之间的博弈 。
第三 , 要傻瓜化操作 , 尤其是对于用户 , 要让用户看见 。 看见 , 哪怕是看见实现的过程 ,也很重要 。
不能一次又一次地走入复杂的区域 。 对用户 , 那还需要什么呢 ?
定义Agent14:45
我们进入第二章 。 真正意义上, 我们去看看 Agent。 刚才其实在前面的 L1 到 L3 的这个推理过程中 ,其实有一些结论已经慢慢慢慢显现了 。
我们还是更把边界收敛一点 。 到这一章叫 " 定义 Agent", 副标题叫 " 从特征到看见 "。 因为你会发现 , 我在第一章的过程当中讲到了很多特征 , 就跟房间里那只大象一样 。
我们可以描述它的腿 , 描述它的尾巴 , 描述它的耳朵 , 描述它的鼻子 , 那些都是它的特征 。 但是你想完整意义上的定义那个大象 , 你需要看见 。
我们还是从两个最不 Agent 的 Agent 方向来看 ,也是我在上一期的 , 呃 ,DeepSeek 的 PPT 中讲得比较多的两个方向 。
一个是搜索 , 一个是 coding。
我们先讲搜索 。 今天这个时间点 , 头部的 AI 搜索公司 Perplexity、JetSpark、 国内的比如说 Meta、 纳米 , 甚至一些知乎等垂类的平台 。
那你会发现 , 针对 AI 搜索公司也有很多的问题 。 从 AI 搜索公司出现的第一天 , 很多人就会问 ,AI 搜索公司需要有自己的模型吗 ?
如果没有的话 , 那不就是套壳吗 ? 对吧 ? 那 AI 搜索的这个机会 , 到底是属于传统搜索引擎公司 , 还是初创公司 ?
这一波 DeepSeek 火了之后, 所有的 AI 搜索公司全部都接了 DeepSeek。 大家的区别是什么 ? 信息源的差别 , 真的能够带来持久的竞争优势吗 ?
产品设计上能够拉开绝对的差距吗 ? 开源的 AI 搜索方案似乎也有很多 。 从工程实现的角度来讲 , 感觉也没有什么难度 。
同时, 专门做法律 、 金融 、 医疗等垂直方向的 AI 搜索 ,是否有意义 ? 你听到这些分歧的时候 , 会不会觉得特别的耳熟 ?
这是 AI 搜索 , 对吧 ? 从 AI 搜索出现第一天 , 这些问题都在 。 我们再看 AI coding。 头部大模型公司的 Chat 产品 , 出现的第一天就可以编程 。
那 AI coding 进化的能力的原动力 , 一定是大模型本身能力的进化 , 尤其以 Claude 3.5 开始的进化 。 那似乎是不是所有做 AI coding 的公司 , 本质上来讲 , 都是 Claude 3.5 或 3.7 的套壳 ?
那这些项目的护城河又是什么 ? 工程 、 体验 、 产品的边界能拉开差距吗 ?AI coding 的开源方案也有很多 , 所有大厂大概率都会做的 。
产品的品牌效应会有吗 ? 做垂直会有意义吗 ? 做前端 、 后端 、 某个垂类场景 , 你会发现差不多的问题被频繁地问起来了 。
但这些问题有答案吗 ? 可能没有
。 所以这回到我最开始讲的 , 我又列了四章 。 之前我在上一次 DeepSeek PPT 里的关于 Agent 那一章节中的几页 PPT, 比如说 1,000 个人眼中 1,000 个 Agent 的概念 ,Agent 的概念被严重泛化了 。
然后典型有一些对于 Agent 的定义 , 包括 24 年 Agent 行业的发展 。 但是你会发现 , 大家在这种谈论当中, 更多的是一种空对空的谈论 ,因为大家的共识都没有达成 。
提示一下, 截止到这个这一页之前 , 我的 PPT 没有提及任何关于 Manus 的内容 , 任何都没有 。 从这一页开始 , 我们看看 Manus 的种种 。
我对 Manus 的第一个描述叫 " 一切的工作为了让用户看见 "。 我在前面强调了很多次 , 看见很重要 。 我截了一张图 ,是 Manus 网站官网上的一个案例 ,是他们分析特斯拉的股票价格 。
呃 , 网页的截图里面 , 你会发现它的整个的 Todo list, 然后它去查各种各样的网站 , 得到各种各样的图表 。
然后图表做好之后, 它会做呈现 , 做一个网页给到你 。 本质上来讲 ,在产品这个层面 ,Manus 的所有的工作都是为了让用户看见 。
截图前面说过 ,L1 的看见是什么 ? 是看见吐字 。L2 的看见是什么 ? 是看见推理 。Agent 的看见是什么 ?
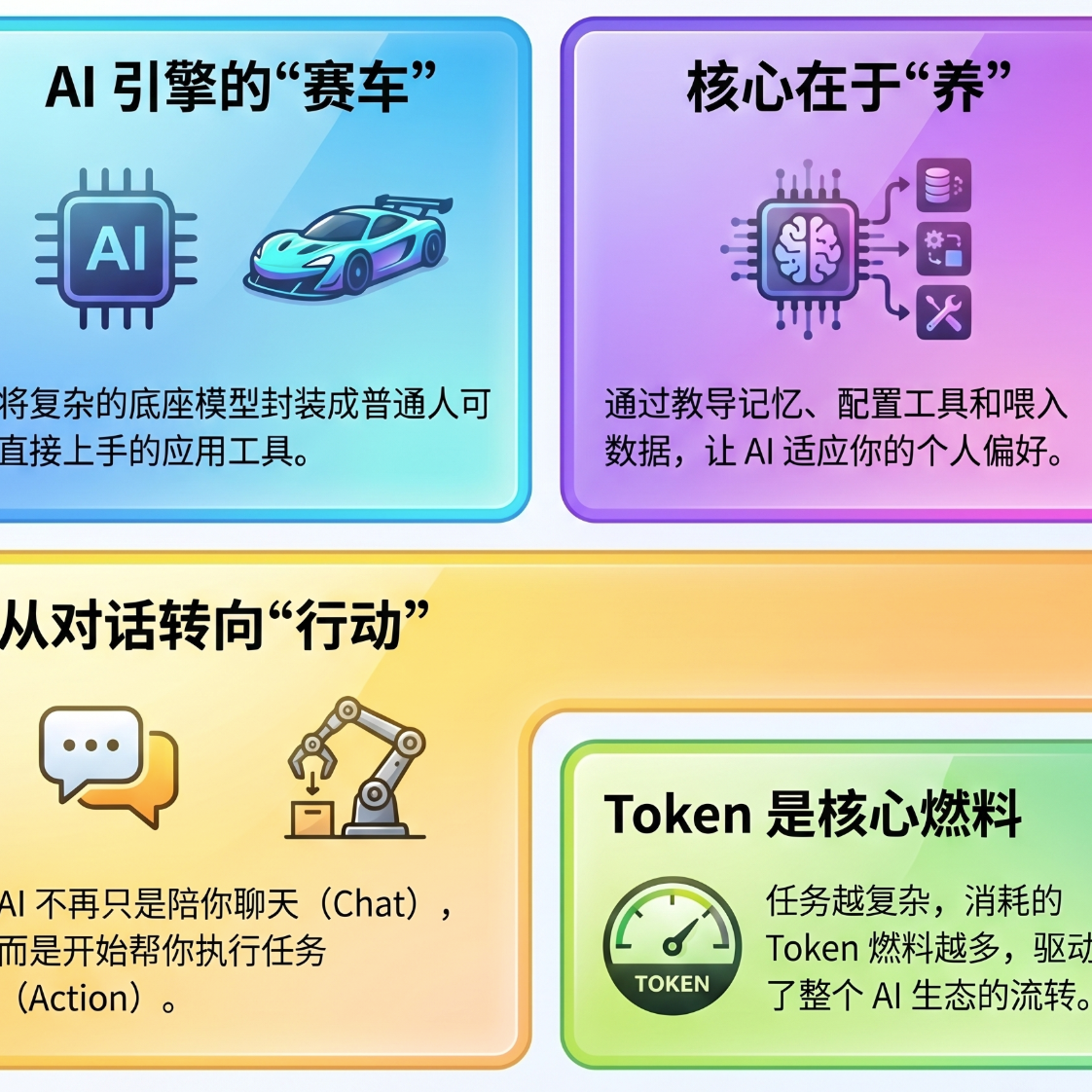
就是看见 Agent 在工作 。 一切工作为了让用户看见 。 那为了让用户看见 , 怎么做到的 ? 我们看第三个部分 , 就是 Manus 的实现原理 。
实现原理20:01
副标题叫 "less structure", 更少的控制 , 更少的限制 。在第三章里面 , 我又分了六个小节 , 分别是技术 、 产品 、 打搒 、 复现 、 成本 , 跟一个小故事 。
我们一个一个来看 。 先看技术 。其实在 Manus 之前 , 已经有很多所谓的 Agent 产品了 , 甚至在 23 年的时候 , 就有了一些开源或者是闭源的 Agent 产品 , 比如说 Auto-GPT、Anthropic 的 Computer Use、OpenAI 的发的 DeepSeek Search、 智谱发的 Auto-GRM,其实都是 。
大家底层的逻辑似乎都是差不多的 , 就 Agent 来拆解任务 、 执行任务 、 给出结果 。 又因为最近一段时间推理模型的成熟 ,在第一步拆解任务这件事情上, 感觉好像没什么难度了 。
同时又因为像 Anthropic 推出的 MCP 协议 , 就是可以让大模型去使用各种各样的工具跟 API。 这种协议出现之后, 包括昨天 OpenAI 发布的一系列的 Agent 框架 , 似乎让模型去使用工具跟搭起架构的这件事情 ,也不是门槛了 。
那很多人会问 , 为什么之前指针没有爆呢 ? 差的是什么呢 ?
就一个 Manus 的例子 。 呃 ,Manus 在发布之前 ,其实就给一些投资人跟很资深的合作方们看过他们的测试版本 。
当时有人就问了一个问题 ,是问这个团队 , 问 Manus 团队 , 你们自己写了多少个 workflow? 大家可以猜一下答案是多少 ?
答案是 0。
还记得我们怎么做到 L2 的吗 ? 先有个 CoT, 然后 PRM 针对过程做激励 ,但发现不对 。 最后方式是不预设任何的限制跟架构 , 只通过结果进行激励 。在这个逻辑上,Manus 跟之前所有的模型公司复现 O1 是一样的 , 没有预设 workflow。
所以反过来讲 , 为什么叫通用 ? 如果你一旦预设了一定的 workflow,其实你就没有那么通用 。 你可能只在几个你预设好的场景边界下会比较好 。
那为什么会这样呢 ? 就是或者说为什么这一页我一定要把那个 less structure 标红 ? 因为在之前关于 OpenAI 发布 O1 之后的几个视频当中,OpenAI 的一位核心的研究人员就表达了这样的观点 , 就不要教它 , 直接给激励 , 尽可能少的给各种各样的限制 。
越少的限制 , 模型表现越好 。 同样的这句话也出现在了 Manus 第二天他们的产品合伙人张涛老师跟 Peake 的分享的闭门分享会的 PPT 里面 , 叫 less structure more intelligence, 越少的控制 , 越好的智能
。 那 Manus 如果从产品形态来讲 ,有一个比较简单的比喻 。 这个比喻是那个 ,也是之前我们 Koji 做 YC 整理的时候借用的一个 KOL 的表单 。
那个 KOL 叫产品二姐 , 她做了一个非常形象的比喻 。 呃 , 当然这个比喻可能是今天这个时间我们看到 Manus 之后, 一个很常见容易想到的方式 , 就是给 AI 一台虚拟机 。
给 AI 一台虚拟机 。 我们回头来看 ,Perplexity 相当于是给 AI 搜索 。 以 Monica 为代表的偏插件跟 Chatbot 的 , 或者说 AI 搜索类的公司 , 可能给 AI 的是一个浏览器 。Cursor 这样的 , 可能给 AI 的是一个 IDE 的编辑器 。
那今天 Manus 给 AI 的是一台虚拟机 。 再举个更现实的现实场景的例子 。 这个例子也是 Manus 团队在第二天的闭门分享会上举的例子 。他说我们之前用大模型 ,有点像我们招了一个实习生 。
这实习生是博士学历 , 懂得非常多 。 但是你在用的过程中, 你在用这个实习生的时候 , 你只给了他笔跟纸 。
那你想他能干什么 ? 你只给他笔跟纸 ,他能干什么 ? 但如果你再给他一个浏览器 ,他又能干什么 ?
如果你再给他一些 , 比如说你们内部的核心的各种各样数据库的访问权限 ,他又能干什么 ? 如果你再给他一些必要的训练跟要求 ,他又会做成什么样子 ?
这一路走下来 ,其实就是 Manus 在做的事情 。 给 AI 一台虚拟机 , 给它浏览器 , 给它必要的数据库访问的权限 , 同时做一定的训练 , 这就是 Manus。
所以那对于用户而言 , 我们具体都看见了什么 , 对吧 ? 我们前面讲了无数次 , 用户看见很重要 。
那用户到底看到了什么 ? 首先看到了 Manus 在规划一个任务 , 会有一个非常详细的 Todo list。 第二步 , 你会看到它执行这个 Todo list, 无论它去查网页 、 调 API、 编程 、 写代码各种各样的方式 , 你都会看到它在哪做 。
第三 , 你会看到它的归纳跟总结 。 它做完所有这些任务之后, 它要一个一个去核对是否完成了 ,并且把所有做的这每一步的工作 , 变成一个整体的归纳的东西 。
最后一步 , 给你一个完整的交付 , 一个 PDF 文件 , 一个网页 , 一篇文章 , 一个文案 , 甚至一个程序 , 一段代码 。Anyway, 给你完整的交付 。
所以你看见了它在规划 , 它在执行 , 它在归纳 , 最后给你交付 。 那好 , 到这你会发现 Manus 做出来了 。
对于 Manus 团队而言 ,他们做完之后, 最直接的马上来的事情 , 那就是看这东西效果怎么样 。 所以在 Manus 官网上有一张图 , 是一个打分表 , 呃 ,是他们跟 OpenAI 的 DeepSeek Search 以及 Salta 做的对比 。
这也是两个类似 Agent 的产品 。 然后他们这个比的这个这个这个搒单叫 GAIA benchmark。在 L1, 这个 benchmark 也分三档 ,L1 是最简单的题 ,L2 是难一点的 ,L3 是最难的题 。
呃 , 我们来看一下这个 GAIA 是什么 。 它其实就是一个题库 , 对吧 ? 然后这个题库大概有 400 多道题 , 让模型去算这些题 , 或者说去考它这些题 , 看正确答案的正确率 , 然后来去衡量 Agent 的能力 。
那刚才我们说过 , 它有三个等级 。 初级的题目通常不需要工具 , 或者就需要最多需要一种工具 ,不超过 5 个步骤就可以实现结果 。
中级呢 , 需要执行 5 到 10 个步骤 , 且必须组合使用不同的工具 。L2 中级 , 那最难的高级 ,是要要求 AI 能够执行任意长度的行动序列 , 使用任意数量的工具 ,并能广泛访问世界知识 。
听起来就很吓人, 对吧 ? 我们看一下具体的例子 , 比如说 L1 的问题大概是什么样 。 它举个例子是 20 世纪 1977 年之后, 唯一一位国籍记录为已不复存在国家的马尔科大赛的获奖者的名字是什么 ?
听懂了吗 ? 初级问题 。 中级问题是什么 ? 在 2015 年大都会艺术博物馆以当年中国生肖命名的展览中,12 生肖中有多少个动物的手是能被看见的 ?
第二个等级 。 第三个等级 ,在 2018 年 3 月上传的一段 YouTube 360 度 VR 视频中, 旁白由指环王中 Guru 角色的配音演员配音 。在视频中第一次出现恐龙后, 旁白立即提到了什么数字 ?
给你一台联网电脑 , 给你哦 ,不是给 AI, 你觉得你能再回答多少对这样的问题 ? 所以这个问题的题特别的难 。
那 Manus 怎么有一个很有意思的小例子 ? 这个在当天的闭门会上,Manus 团队也讲过 。 呃 , 当时他就测了一个 GAIA 的 L3 的题 。
这个题是什么呢 ? 是在一个类似国家地理风格的 YouTube 的视频链接里 , 各种企鹅们来来回回的走出又走进画面 , 让 Agent 数一帧 , 画面里面同时出现了最多几种企鹅 。
听明白这个问题了吗 ?
然后 Manus 怎么做的 ?Manus 先打开这个视频链接 , 接着做的第一个动作 ,是按了一下键盘上的 K, 接着挨个截图记录哪一帧出现了哪种企鹅 , 最后得出最多的一帧画面有三种企鹅 。
这还没有完哦 。 做完之后,Manus 回去检查 ,他的下一个动作是按了键盘上的 3, 最后确定答案 。 我不知道是否用 YouTube 啊 , 或者是否用视频网站 。
你是否知道 YouTube 的快捷键里面的 K 跟 3 是干嘛的 ?K 是暂停 。 当然有人说空格也暂停 , 对 , 空格也是暂停 ,但空格有可能会引发旁边的那个拉的条的变动 。K 完全只针对视频做暂停 。3 是什么呢 ?YouTube 的 1 到 9 的快捷键对应的是 10% 到 90% 的视频进度 。
这是 AI 在做的事情 。
那除了这个 GAIA 之外,Manus 团队还做了什么 ? 这个其实没有太多人讲 ,因为只有他们当天的闭门会上讲到了 。
大家知道今天 YC 应该是今天这个时间点 ,在孵化器领域投 AI 项目最多的孵化器了 。 它的一期项目里面可能有一两百个项目 , 现在 70% 到 80% 都是 AI 项目 。
如果大家有兴趣 , 可以去翻去年我跟 Koji 做的总结 。 我们总结是 24 年, 然后在 25 年的最新一季的 YC 项目当中, 可能有 100 多个关于 AI Agent 相关的项目 。Manus 团队做了这样一件事情 ,他把这些项目全部拉出来 。
因为你的这些项目可能是做医疗 、 做法律 、 做销售 、 做金融 , 甚至做一个什么 4S 店销售更小的这样一个场景 , 无论你做什么 , 你总归会有个官网 。
你的官网上总归会有关于业务的介绍 , 无论是图片 、 是视频还是文字的描述 。Manus 团队把所有这些 YC25W 级的 Agent 项目的描述全部拉出来 , 让 Manus 重新去做复现 。
最后得到结果是 ,他大概可以 cover 76% 这些不同各种各样的 Agent。 这一步
叫通用 , 对吗 ? 或者说有一点像之前 DeepSeek 做出 R1 之后, 同时去训练 Llama 跟千问做的事情 。
然后再考虑到下一个小的话题 , 成本的话题 ,也是 Manus 团队提出的 。他说 Manus 团队会认为 , 今天这个时间点 ,在 Agent 年代 , 尤其在 AI 的 Agent 年代 , 衡量一个业务的指标 , 可能不应该去看常规意义上的什么 DAU 啊 、MU 啊 、 留存啊 。
有个核心的指标应该叫 AHPU,Agentic Hours per User, 就一个用户用 Agent 的时间 。 你想一下, 比如说我们现在用 DeepSeek 也好 , 用豆包也好 , 用夸克也好 , 用混元也好 , 用元宝也好 , 你跟他的对话一次的消耗的时间是多久 ?5 秒 、10 秒 、20 秒 , 撑死 30 秒 , 对吧 ?
但是如果大家用过 Manus 的话 , 你会发现一个复杂任务交给 Agent,他快的可能也要十几分钟 , 慢的可能要几个小时, 甚至更长的时间 。
那你想想 , 这中间的算力的成本的差距是多少 ? 可能不是十倍 、 百倍 , 甚至是一千倍 、 一万倍的差距 。
同时又因为这样的时间的差距 , 呃 ,Manus 自己的统计是说平均来看 , 呃 ,DeepSeek Search 每个问题所消耗的成本 , 平均在 20 美金左右 ,Salta 大概 10 美金 ,他们现在大概 2 美金 。
呃 ,有一些开源方案复现了 Manus 的功能之后, 有一些技术员 、 技术人员去重新用开源的方案去做实施的时候 , 我印象当中看过一些方案 , 可能做一些任务也需要三四美金的算力的成本 。
那这这个成本的巨幅的扩张 , 引发的另外的一个问题就变成了 , 年初我在呃做那个 24 年总结的时候 ,有一页 PPT。
呃 , 那页 PPT 内容是转发涅榈的创始人修涵 , 对于 token 这个市场的估算的 。他在今年年初的时候做了这样一个估算 ,他说 , 呃 ,在今年年初那个时间点 ,在中国国内 , 基本上我们不算大模型厂商自己的应用 , 算第三方调用的话 , 如果一个应用每天能够消耗百亿的 token, 那基本上就是一个垂类比较大的 APP 了 。
百亿 token 大概就是你的算力的成本是 5,000 块钱一天 , 这种 APP 大概可能有几百个 , 每天就是小几百万的消耗 , 全年这个盘子就是几十亿到将近 100 亿的盘子 。
这就是第三方调用大模型的这个商业模式 , 可见的在那个时间点的天花板 。 而且重要的是 , 大家会说 , 呃 , 我在上一期的播客里也有讲过 ,OpenAI 的 Sam 也提过 , 基本上每 12 个月算力的成本会降 10%, 呃 , 会降 10 倍 。
如果再考虑到比如多模态的迭代 , 可能又是 10 倍 。 所以每年是以百倍的方式在降 。 那极端设想 , 修涵说一个用户两个小时全部用视频生成的方式去用 AI 的方式调用 , 大概是 30 亿 token 每个用户 ,100 万的 DAU 的产品是 3,000 万亿的 token 消耗 ,是当下的 30 万倍 。
那个就是个极限状态 。 那今天你会发现 , 原来大家会担心 , 如果今年的成本降百倍 , 这个第三方市场的业务增长能不能达到 100,是个问号 。
但是有了 Agent 这样新的衡量方式之后, 你会发现 100 倍真的太容易了 。 那如果再发散一下, 我们前面提及的 AHPU 这个这个这个指标 , 更像是一个单线程的指标 。
那如果多线程并发呢 ? 因为大家如果用 Manus 的话 , 你会发现很多 Manus 的那些用户 ,是同一时间让 Manus 执行很多个任务 。
那如果你作为服务提供商 , 你的允许的最大并发应该是多少 ? 如果你再考虑到这些并行过程中是有用户的干预 , 会重新启动一些新的进程 , 那似乎这个数字可以无限算下去了 。
所以出现一个结论 , 这是我的好友公式粉丝区的作者周末前天发的 。他说因为他在美国跟很多投资人去沟通 ,他会发现无论我们如何评价 Manus,不管怎么样 , 这一周可能是讨论 Agent 带来 token 变化的第一周 , 我们真正意义上开始讨论 Agent 对 token 变化的影响 。
最后讲一个小故事 ,Manus 团队最早不是在做 Manus 的 ,其实他们最早是想做浏览器的 ,是做 AI 浏览器的 。 而且是很巧合的是 , 如果对这个行有了解的话 , 应该知道美国之前有一个很有名的 AI 浏览器叫 Arc,但是 Arc 已经确认停止更新了 。
也非常巧合的是 ,Arc 确认停止更新通告的那一天 ,也是 Manus 团队决定不做浏览器的那一天 。 为什么大家会发现浏览器不太适合作为 Agent 的承载 ?
其实从用户体验层是一个非常好理解的状态 。 大家今天用 Manus, 你把它交任务交代完 , 你就可以走了 。
但是如果它是个浏览器 , 它要占用你的屏幕 , 你不能干别的任何事情 , 你甚至不能断开网络 , 你不能做任何的别的操作 , 你会打断它 。
但是 Manus 选了另外一条路 , 我给它虚拟机 , 它在虚拟机上跑就好了 , 你只要任务下载完成 , 它就可以搞了 。
所以浏览器变成一个中间态 , 被放弃掉了 。 这是一个故事
。 所以反过来讲 , 回到我的标题 , 如果大家还有印象 , 我这期的标题叫 Manus 没有秘密 。 为什么说 Manus 没有秘密 ?Manus 的核心团队有三个人 :CEO 小红 、 首席科学家 Peak、 产品合伙人张涛老师
。在 2 月份 , 小红接受小俊的播客采访 ,他就提及到了 。他说 AI 今天那个时间做 Agent, 现有的能力还不够 , 应该有个虚拟机 ,Chatbot 应该在云上有个电脑 , 把它写的代码 , 把它要通过浏览器查的东西 , 都在电脑上执行 。
因为是虚拟机坏了也无所谓 , 它可以再来一台 , 它甚至可以在当前任务执行完之后试掉那个 , 试释放掉那个虚拟机 。
所以我自己觉得那个架构叫做一个虚拟服务器 , 一个浏览器 , 能够自己写代码去调用 API, 能够胜任胜任各种各样的长尾任务 , 这就是我们在做的事情 。2025 年 2 月 ,Peak 在 2024 年 10 月份开源了一个模型 ,也是复现 O1,是做的推理模型加强化学习 。
今天这个时间点 ,在 Manus 上的很多任务的执行 , 跟更少的架构的控制 , 就是用了这套开源的模型 。24 年 10 月 , 张涛老师在 2 月份讲 DeepSeek 的 PPT 的最后一页 , 提到了 DeepSeek 给他在产品使用上启发 。他说要提供绝佳的产品价值 , 用我的理解来看 , 就是那个看见 。
张老师说 , 要想 95% 的人用到第一款 AI 应用 , 应该是什么样子的 ? 如果做 Agent, 获得外部世界的观察很重要 , 还能加什么 ?
所以你发现在 Manus 发布之前 , 这三位核心的创始人已经把 Manus 所有的执行技术路径 、 实现原理 、 方案 、 产品设计都讲过了 。
所以 Manus 没有秘密
。在 Manus 火了第二天 ,他们发了一个公告 , 我想在这里
重新读一下 。 张涛老师在 3 月 6 号发的 ,他说首先给关注 Manus 用户和媒体老师们一个歉意 。 我们知道很多人没有体验到 Manus, 过去的 17 个小时, 对于团队来说无异于一场充满了各种意外的冒险 。
我们完全低估了大家的热情 , 一开始的初心只是分享一下 ,在探索 Agent 产品形态过程中的阶段性收获 , 阶段性收获 。
因此服务器资源完全是按照行业里发一个 demo 的水平来准备的 , 根本不曾想会引发如此大的波澜 。
目前采取邀请码机制 ,是因为此刻的服务器容量确实有限 ,不得已而为之 。 最后一段 , 大家目前看到的 Manus, 还是一个襁褓中的小婴儿 , 离我们正式版中想交付给大家的体验还差得很远 。
像模型幻觉 、 交付物友好度 、 运行速度等方面 , 都还有很大的提升空间 。 我刚才讲完所有前面的故事 , 你就能理解为什么在那个时间点 ,Manus 发了这样一个公告 。
使用体验41:27
好 , 进入我们的第四部分 , 那我们就来用一用这个 Manus。 我找了一些身边朋友的案例 , 刘飞老师 、Junyu、 李继刚 、 大聪明 、 兰溪跟我 , 所有人都在极客上 。
所以马总要记得给我打钱 。 先看刘飞老师 , 刘飞老师做了几个案例 , 我挑了两个 。 第一个是他希望让 Manus 给当下的 AI 大模型打分 , 然后并且产出了一个报表 , 看上去挺像模像样的 。
第二个需求是做一个播客行业的总结 , 平台市场份额 、 内容分布 。 那这种偏我叫基础信息的收集跟整理 , 对于 Manus 而言 , 今天来看是一个相对门槛比较低的事情 , 做的比较好 。
然后我们再来看看 Junyu 的这个这个 demo 啊 ,Junyu 的公众号叫猫窝 , 大家还是可以去看他对 Manus 的体验 。他做的几个案例当中, 有几个比较有代表性的是我叫复杂信息的收集整理 , 就不是简单的信息整理 。
比如说他有一个任务 ,是让他收集几个 APP 的官方图标
, 然后从这个结果来说 , 可能只完成了 70% 吧 ,因为有一些图标 , 比如说格式不对 , 然后模型会偷懒的把字自己把那个文件名的拓展名改掉 。
然后他第二个任务 ,是让他到海关的官网获取一些贸易伙伴的月度的出口额 。 呃 , 从执行者角度来看 ,他找错了地方 ,他没有真正意义上去海关的官网去找这些东西 。
所以从数据来讲不是特别理想 。 所以从总结来看 ,Junyu 的案例来说 , 就是复杂信息的收集整理类 , 对于 Manus 而言可能还不那么容易 , 或者说你需要给 Manus 更明确的目的地的指引 , 比如说海关那个案例 , 你就要告诉他你就来这找 。
然后李继刚老师作为这个提示词之王 , 对吧 ,他做了两个测试 , 一个是作为这个 , 比如说中国的古代的金句的 PDF 制作 , 那这个任务完成的非常好 。
金句的制作 , 包括做成 PDF 的格式的展现非常好 。 然后他让 Manus 用 HTML 加一些这个可视化的图片去讲解 , 强化学习 。
嗯 , 从做出一个 HTML 网页讲解一个概念 , 这个任务本身而言是完成的 。 但是呢 , 你会发现那些图跟图标还是有待加强的 。
然后大聪明就是赛博产新 ,他给了一个更狠的测试 , 让他做了一个 DOOM,DOOM 就是最原始的那个设计游戏 。 那最后跑出来一个东西 , 这个可以东西可以运行 , 除了没有枪械的这个图的这个枪之外 ,他可以左右移动 , 可以用键盘去控制 ,有地图 , 这东西能跑出来 ,其实就已经非常不错了 。
这是大聪明的案例 。 然后呢 , 呃 , 我想多讲一点的是我和兰溪老师的 , 兰溪老师的这个案例 , 我们俩用的是一个案例 ,而且我们俩之前是没有沟通的 ,是不约而同给了 Manus 这样一个任务 。
这个任务是什么 ? 很有意思 , 这个也就是在前几天 ,A16Z 呃发布了每半年更新一次的 TOP 100 AI 应用搒单 , 它分 TOP 50 的网页 AI 应用跟 TOP 50 的移动 APP AI 应用 。
然后这个搒单发出来之后, 我们同时给了 Manus 一个任务 ,是什么呢 ? 去看这个搒单当中有多少是中国公司或者中国团队做的 。
大家细想一下这个任务啊 , 首先这个搒单是刚刚发出来的 , 暂时在那个时间点还没有专业的媒体做分析 , 当然今天已经有了 ,在那个时间点是没有的 。
然后呢 , 你想这个任务的执行过程 , 首先 Manus 要识别这些应用图标 , 对吧 , 跟名字 , 然后去搜索对应公司官网或者新闻报道 , 然后再去确认是否是中国团队 ,并且要一个一个的筛 , 对吧 。
同时更重要的是 , 我刚才讲过这个 100 的搒单 ,是有 50 个 Web 跟 50 个 APP,但你要知道 ,50 个 Web 跟 50 个 APP 里面是有重复的 , 比如说 ChatGPT 一定它既在 Web 里面也在 APP 里面 , 所以模型还要去核对 Web 跟 APP 的重复 , 再最后整理在一起给我结果 。
所以如果没有完全公开的确认信息 , 还要做一些模糊的判断 , 比如有团队可能在新加坡 , 对吧 , 那这些团队怎么算呢 ?
然后现实世界里 , 如果这个任务专门看 AI 出海 , 或者看这个方向的投资人跟媒体人, 人肉是可以做出这样标注的 , 对吧 ,但你觉得这样的人有多少在中国 ?
或者说如果你希望找到这样的人, 请教需要付出什么样的成本 ?
如果你给一个实习生来做这个工作 , 你觉得他需要多长的时间来把这个工作做完 ? 我觉得这道题按照刚才我们聊的那个 GAI 的那个测试库的标准 , 应该已经算 L3 了 。
我们看看结果 , 我觉得啊 , 我们先不看结果 , 我同样把这个问题甩给了今天这个时间点的 AI 搜索工具 , 比如说我给了腾讯的元宝 , 给了豆包 , 给了 DeepSeek, 给了夸克
, 表现最差的是腾讯的元宝 , 它告诉我 10 个 ,但是细看它给的 10 个举个里面有 6 个并不在那 100 的搒单里 , 它胡说八道了 6 个 。
数字层面 , 结果给的最多的是豆包 , 给了 19 个 ,但是里面也有 6 个并不在那个搒单里 , 甚至是张冠李戴的 。DeepSeek 跟夸克也不是特别理想 , 大家也要想为什么会有错误 , 为什么会胡说八道 , 对吧 , 幻觉
。 那 Manus 做到什么程度呢 ? 我第一次交给的任务给我返回的结果 , 这个数字是 9 个
,9 个是怎么来的 ? 特别简单 ,A16Z 发布这个搒单的时候 ,是配了一篇文章的 , 那篇文章里是关于这个搒单的解析跟描述的 , 那个搒单里提及的中文应用是 9 个 。
比如 Manus 第一次给我任务的返还 , 是一个偷懒的结果 , 我看到这个结果 , 我说你要一个一个排查 , 所以我给了第二次的提示 , 就是第二次的任务的追加 。
然后他说好 , 我一个个查 , 然后第二次给我返回的结果是 16 个 。 第三次我说你要继续查 , 肯定还有 ,他又去查 , 第三次给我返回了 21 个 。
然后时候我问了第四次 , 我说他确定没有了吗 ? 然后他又去查了 , 最后给我返回了 23 个 。 到这一步的时候 , 系统提示上下文的长度受限了 。
从结论上来说 , 真实的数字应该比 23 还要多 ,但应该已经是非常接近的数字了 。 所以你看到这个过程会有什么感觉 ?
刚才那些似乎都是好的结果 , 对吧 , 那有什么不好的吗 ? 有当然了 , 比如说在我跟李继刚老师的这个任务当中, 我们都发现 , 比如说我们都希望让他做一些示意图 ,但是我没有告诉他应该去哪做这些图 , 所以他就用简笔画的方式画了一些简笔画的图 , 非常的难看 , 非常的简易 , 对吧 。
比如说我做了一个类似 Junyu 去海关数据 , 我是让他找春运数据 , 同样他找错了地方 , 给我的结果不好 。
然后比如说我让他做一个 PPT, 我希望他有截图跟那个来源的网页的内容 ,他就直接把一个网页截截过来 , 结果那个网页上是没有登录的 ,有二维码贴在上面的 , 然后所有的图的位置也不对 ,也没有太多的排版信息 , 这都不是一个理想中的结果 , 对吧 ,但你看上去他在他在认真的干活 , 只不过做的不太好 , 对吧 , 那有没有更差呢 ?
当然也有了 。 最常见刚才我说 , 嗯 , 上下文的限制是受到大模型本身的限制的 , 所以经常会发现一个任务执行多次之后, 它会提示你特别长的上下文当中, 你最好用新的对话 , 比如说虚拟机可能会遇见问题 , 虚拟机需要重启 , 重启不起来它就一直重启 , 然后可能因为用户的负载过高 , 它就需要歇几分钟再试 。
所以它不是完美 , 它没它它甚至很不完美 , 它有很多的问题 , 成功率也没有那么高 。 因为你像 GAIA 的标准 L3 的题 , 它大概只有 57% 的成功概率 , 所以还有 40% 多的是不成功的 , 对吧 。
所以那到底我们该如何理性的看待这件事情 , 或者说看待 Manus 呢 ? 我用一个也是一个这一波比较早测试 Manus 的自媒体博主一泽的观点 ,他说就是一个实习生的水平 , 缺乏实战经验 , 缺点灵性 , 是一个 24 小时高吞吐量干活的在校大学生 。
最终产物的水平 , 取决于作为 Agent 内核的水平和可接触的数据质量 。 这是一个相对我觉得理性的评价 。
暴论输出51:34
好 , 我们聊完使用 , 聊到今天的最后一章 , 我叫暴论输出 , 全是死活
, 列了几个关键词啊 。 第一个关键词干啥啥不行 , 第二个关键词不就是套壳 , 第三个关键词开源 3 小时复现 , 第四个关键词没有技术创新 , 第五个关键词肯定是炮灰 , 第六个关键词营销肯定花钱了 。
我们一个一个来讲 , 干啥啥不行
, 确实你会发现今天这个时间点 , 对于一个通用的 , 或者定义叫通用 Agent 的产品而言 , 你很难在每一个垂类的 , 尤其是特别特别垂直的场景下, 要求它做的尽善尽美 。
但这里面出现一个问题啊 , 这个问题是一个呃 , 或者这个场景是一个很有意思的场景 。Manus 火的当天啊 ,有一位这个记者朋友打电话跟我聊 , 跟我问 ,因为他知道我有优先码 ,他知道我在用啊 ,他是一个没有那么关注科技行业的 , 算是一个大众媒体的记者 , 所以他对很多科技行业理解不是那么深 ,也不是一个专门跑 AI 线的 。
所以上来他的第一个问题 , 是一个非常朴实的问题 : 好用吗 ? 我听到这个问题的第一反应是 , 我先要想怎么去回答这个问题 , 我先停顿了一下, 然后我提了个假 , 这个假是什么呢 ?
就是说我跟他说 , 我说现在的很多测试案例都会有更好的解决方案 , 所以这个问题的答案只能代表我自己 。
但请记住他们所强调的通用 , 什么意思 ? 就说比如今天让他做个 PPT, 我做 PPT, 做 AI PPT 一定有专门做 AI PPT 更好的方案 ,但是他不是专门为 AI PPT 做的准备 , 对吗 ?
这就引发了一个其实 95 年比尔盖茨去上一个节目 , 讲述互联网的那个故事 , 就主持人问说 , 听说前两天互联网发生了一个重大的新闻 ,是可以啊直播听到棒球比赛的现场的比赛 , 然后比尔盖茨说是啊 , 然后那个主持人问 , 那所以我的收音机是干嘛的 , 对吧 ?
然后他说 , 还说最近什么上了一个汽车网站 , 可以查各种样汽车的数据 , 比尔盖茨说是啊 , 然后那个主持人说 , 那我的汽车杂志是干嘛的 , 我觉得是一样的通用 。
什么叫通用 ?
第二个关键词不就是套壳吗 ? 这个应该是太多次的出现 ,在过去这一段时间的各种各样的地方 ,不就是套壳吗 ?
我的答案特别简单 ,不就是这三个字 , 是一种偷懒 , 套壳是傲慢 。 什么叫套壳 ?Publicity 是不是套壳 ?Cursor 是不是套壳 ?
元宝以及一堆接了 DeepSeek 的应用是不是套壳 ?
针对这个话题啊 , 我在推特上跟集合上找了三个我的同行投资人的观点 。 首先是雨森的 , 雨森是 Manus 的投资人, 所以他是立项官方 。他发了这样一段话 ,他说 2013 年 1 月我看到一个产品叫 Publicity, 用起来觉得挺有意思 , 于是立刻去问了一位对搜索和 AI 都很有经验的大牛朋友 ,他看了一眼说有点意思 ,但这个没有壁垒啊 , 我周末可以搓出一个出来 。
后来他周末还真的发了一个原型给我 。2023 年中一位好朋友问我 ,有机会小几亿美金估值投 Publicity 感兴趣吗 ?
我那时已经经常使用 ,但想起那位大牛说的话 , 于是我礼貌的拒绝 。 哎呀 , 套壳应用是不是没有壁垒啊 ?
然后光速的一位合伙人在推特上也是这样说的 , 技术可能很多时候都不是绝对意义上的终极的指标 , 真正能够形成护城河的
,是产品
,是网络效应 ,是销售渠道 ,是品牌 ,是这些东西 。 另一个做美元基金的合伙人更直接 ,他说 Cursor、Gleam、Publicity、Moonworks 好像都是套壳 ,但是他们已经 5,000 万美金的 ARR 了 ,他们已经估值 10 亿美金了 。
当然有人会说你们这帮做投资的懂个屁 , 对吧 ?Anyway, 当然了 , 就是纯正意义上的套壳还是依然非常热火的 。
同样在 H2Z 的这个新一期的 Top 50 的 APP 搒单上 ,有 6 个是纯正意义上的套壳 , 就是 APP 的图标也很像 GPT 提供的功能 ,也就是大模型的真正意义上的套壳 。
那个东西叫套壳
, 开源复现 3 小时, 对吧 ?3 小时开源复现 Manus, 开源的方案跟的很快 , 对吧 ? 现在最有名的是两个 Open Manus 跟 OWL, 强吗 ?
很强 ,但是我想说的是 , 你想用对于一个用户而言 , 对一个普通的用户而言 , 想要用起来这些开源的方案 , 你首先要在 GitHub 上下载这些代码 , 要在本地进行环境的搭建 , 要在云端做服务器的部署 , 要去调用各种各样模型的 API, 最后还有可能用命令行的方式做执行 。
听起来门槛似乎有点过于高了 , 对吧 ? 然后我再引用格飞的一句话 ,他说手搓个 Demo 很快 , 运营好一个产品是很难的 , 说自己也能手搓的 , 只考虑到了 424 时间分配原则里的 2。424 是什么呢 ?
第一个 4, 挖掘需求 。在别人挖掘出这个需求 , 做出这个产品之前 ,他没有去搓一个出来 。在别人发布之后, 照虎画猫当然会容易 。
第二个 2,他也只是实现了最核心的一点功能而已 , 别人背后做的大量细节工作 ,他没有看到 ,也没有去复现 , 所以画虎不成反类权 。
第三个 4 是宣传推广 ,他完全没有考虑到这是一项长期的工作 。
再引发很多人会说这件事情没有真正意义上的创新 , 创新到底是什么 ? 我们只看过去这两年的 AI 大模型行业 , 那样一个非常非常简单的基于大模型的粗暴的递进关系 , 似乎只有一个局势是 , 就大模型才叫底层技术 , 才叫创新 。
所以在之前会有结论会说 ,在大模型的技术能力没有收敛之前 , 大家应该谨慎做应用 。 那我就想问了 , 那产品又是什么呢 ?
不是大家都在期待 25 年是 AI 产品 、AI 应用 、AI Agent 爆发吗 ?
再举两个更现实的案例 , 一个也是一个极客网友在回复一条 Manus 评论里 ,他说 :" 我问了一下平时不关心 AI 的做财务负责人的朋友 ,他看了 Manus 说是我期待的 AI 的样子 。
我的另外一个好朋友是做大学老师的 ,他说我昨天回复旦和老师们吃饭 , 我就给他们安利各种 AI 的用法 , 老师们说他们已经跟不上时代了 ,但是很想试试 Manus, 就是那种傻瓜一点的 , 人没有什么干预能力的 , 完成质量差一点的也没关系的人物 。"
更重要的是 , 第三条是一位 Manus 的团队的前员工发的 ,他说从我的视角上,Manus 就是 Monica 这个公司抓住机会能力上最好的体现 。
但这么解读 Manus 太浅薄了 ,因为他们的工程实践和 Agent workflow 的积累是实实在在的 。 我参与到的就有 23 年 9 月到 10 月首次在国内推出 Agent, 这里面 Todoist 都是当时学习了各家 Agent 方案之后的最佳实践 。
再到 24 年 3 月做 GPTs 平台 ,24 年初开始一直就在做浏览器的技术积累 , 积累大量对浏览器 Context 利用的理解 。23 年 11 月开始做搜索 , 对 Agent 联网获取信息的能力也是需要积累的 。
我没有参与的部分 ,24 年 7 月份通过 Rust 获取社交流量的增长经验 。24 年 11 月 Coding 产品中对于各模型 Coding 能力的理解 , 确实每件事都是相对薄的一层 ,但是这些积木在这个窗口形成的组合创新足够强 ,也是事实 。
但也就是他们可能既有认知 , 又有足够的工程能力 ,在这个小窗口实现空隙
。 我们再把这个问题更抽象一点来看 ,L3 是 Agent, 好 , 那 Agent 到底是一个模型还是一个产品 ?OpenAI 发布 DeepSeek 的测试之后, 核心团队接受了一些播客的采访 ,OpenAI 官方明确说 DeepSeek 是基于 O3 模型的微调模型 ,是模型 。
所以又回到老生常谈的问题 , 模型即产品了吗 ? 那如果是这样的话 ,AI 行业的叙事还有纯粹意义上的产品叙事吗 ?
或者再委曲求全一点 ,有没有技术加产品的双叙事呢 ?
没有产品叙事什么事会发生什么 ? 就跟那张梗图画的一样 ,STARP 建立在 LLM 上能力会瞬间被大大于模型冲掉 , 对吧 ?
那如果是双叙事呢 ? 或者像像 DeepSeek 火了之后广密讲的
, 模型即应用 ,DeepSeek 在产品上没有任何创新 , 核心就是智能加开源 。 我也不禁思考 ,在 AI 时代 , 任何产品和商业模式的创新都比不上智能的创新吗 ?Manus 的事件会是这样一个技术加产品的双叙事结构的开始吗 ?
无论什么叙事 , 好不公司都会做的 ,OpenAI、Publicity、Google 的这个产品都叫 Deep Research。OpenAI 公布的下一代 GPT-5 里面 ,GPT-5 是一个融合的模型 , 它有 Pro 有 Plus 有 Free, 它包含了 O3, 包含了 GPT-4.5, 既要又要还要 。OpenAI 最近又说 ,他们要推一个 2 万美金一个月的博士模型 , 对吧 ?
头部公司都会做的 。 那所以那怎么去衡量跟权衡 ? 所以到最后又回到了我上一次 PPT 的那一页 , 至少在海外,ARR 依然是最粗暴的标准 。
我们看收入好了
, 大厂一定会跟进的 , 这是一句正确的废话 。 夸克 、 元宝 、 豆包 ,25 年的核心的工作的 OKR 已经非常清楚了 ,不需要再去跟老板解释了 , 对吗 ?
所以这个方向来看啊 , 张涛在 Manus 火之前去馄饨有一次演讲 ,他说了这样一段话 ,他说常年做创业项目的同学应该有这种感受 , 如果一个项目做了一年却没有任何竞争对手 , 反而会让人不安 , 你会开始怀疑我选的市场是否真的有问题 , 为什么连竞争对手都没有 。
从推演的角度和实际入局的角度来看 , 感受截然不同 。 比如我们已经投入半年, 还在犹豫是否继续时, 突然有大厂进入 , 很多人可能会觉得慌 ,但其实我们只会觉得庆幸 , 终于证明我们的方向是对的 。
所以在局中时, 感受真的会非常不一样 。 用一个更清晰的或者更简单的梗去解释这件事情 , 我记得有个朋友说过 , 美女有什么标准吗 ?
美女是没有标准的 , 你看到是美女 , 那就是了 。 最后最后最后说一说营销的事情
, 这应该是这一波关于 Manus 讨论当中非常重要的一个话题 。 我列一下时间线 ,3 月 5 号的中午 12 点 , 张涛老师给我发了一条微信 ,他说我们晚上 10 点会发布他们新的产品 , 明天也就是 3 月 6 号的 10 点半 , 会向朋友们进行第一轮交流沟通 。
如果你有兴趣 , 我把腾讯会议的号码发给你 ,3 月 5 号中午发的 。3 月 5 号晚上,
创始人小红跟张涛老师在极客上发布了这条视频 。 小红是 3 月 5 号晚上 11 点发的 , 张涛老师是 3 月 6 号凌晨 0:17 发的 , 极客上发的 。
然后在 3 月 5 号晚上的 9 呃 11:50 的时候 , 赛博禅新的大聪明 , 公众号赛博禅新大聪明 , 转发了 Manus 的这个官方视频 , 又在 3 月 6 号的 7 点发了一个测试
, 就是他测试的 Manus 这个 Demo。 然后卡兹克是在 3 月 7 号的早上 6 点 ,他通宵没睡 , 没有睡 , 做了一期体验的内容 。
这是第一波的传播的所有内容 , 所有内容仅此而已 。 截止到这个时间点 , 我们能看到的介绍全部来自于这两两条极客以及两个公众号的推送 。
然后其实视频发出来之后就爆了 , 然后就是第二天的那个演示会 。 所以第二天的闭门会是早就预期好的 ,不是一个澄清会 ,他是早就想给朋友们介绍一下他这个东西的 。
参与现场的我可以列几个我身边比较好的 , 比如说徐凯老师在 ,Koji 在 , 华生在 , 特工宇宙在 , 一泽在 , 黄叔也在 , 我也在 , 还有一些朋友 , 我们都会在 。
有人在北京的线下 ,有人在线上 。 我可以保证的是 , 我们所有这些人没有任何人收收了 Manus 的钱 , 没有 。 所以在那个时间点 ,Manus 也发了个公告 , 说我们从未开设任何付费获取邀请码的渠道 , 我们从未投入任何市场推广预算 。
作为亲身参与其中的个体 , 我绝对的相信这个团队的这个公告 。 从结果来看 , 华生那条极客也很有代表性 ,他说其实一切的开始 , 就是团队做了一个挺好的产品 , 拉圈子里的朋友们聊了聊 , 请大家测一测 , 事情的发展应该是完全超出他们的预期和控制 , 仅此而已 。
那为什么大家愿意呢 ?
我用了两个两个两个字的关键词叫善缘 ,也是在我上一次 DeepSeek 的 PPT 里 。 我推荐大家如果对 DeepSeek 的技术实现想要了解的话 , 去看一个两个小时的视频 , 那个视频的名字叫 《 最好的致敬是学习 》。
那个视频是谁做的 ? 是张涛老师做的 。 更重要的是在我的播客里 , 上上期内容关于 DeepSeek 的遥远与误解 ,是我和 Lily 以及张涛还有另外一个老师做的 。在过去这一段时间里面 , 张涛老师通过这种方式 , 某种意义上说 , 结了足够大的善缘 。
我们这些对技术理解没有那么深的非技术人员 ,是要感谢张涛老师的布道的 。 所以为什么这种会有这种信任 , 会有第一批那么强的自来水 ,是因为善缘 。
当然很多人可能不信 , 那我用另外一个反过来的方式去说 ,因为在 6 号的早上 8 点 , 知乎上就有问题问 Manus, 当时排名第一的答案是说 , 第一款自媒体比技术从业者先发现和评测的 AI 产品 , 没有错呀 。他说在 Hacknews 跟 V2EX 上没有热度 ,因为他们的朋友不是技术圈的 ,他们的朋友是我们啊 。
再举个例子 , 这波的传播从极客 、 公众号 、 小宇宙作为开始
,3 月 8 号早呃 3 月 6 号早上, 从这一个最小的圈子开始 , 先拖到了核心的科技媒体圈 , 然后拖到了财经媒体圈 , 到当天有一些党媒央媒报道 。
如果你想一下这个营销是设计过的 , 你得用多少的钱 , 前期得铺多少的关系 。 我知道有很多大厂的公关是听我播客的 , 今天我给你足够多的预算 , 你能复现这样的传播吗 ?
答案不言自明 , 对吗 ?
还有人会说推特上根本没有讨论啊 ,因为他们没有给在那个第一时间给外面的人, 外国的推特上的用户测试啊 , 所以怎么会有讨论呢 ?
直到后来推特上出了很多讨论 。 所以我想说的说 , 大家一定要用出口转内销的方式来验证一些事情吗 ?
就没有自己独立判断的方式跟逻辑吗 ?
共勉1:11:14
最后,Agent 年代真的要来了吗 ?
我用下来 Manus 的感受是这样的 , 我说
, 我更清楚的知道如何面对这样一个时代 。 你要学会做一个好的老板 , 提出好的问题 , 分配好的任务 , 给予充分的信任跟授权 , 过程中及时的调整 , 收到结果后给予反馈 , 如此反复 。
这是我作为一个非技术从业者 ,但是对 AI 行业感兴趣 ,并且用了很多 AI 工具的人的一个切身的感受 。 然后同时我更想引用玉果老师对于 Manus 的评价 ,他是这么说的 ,他说最近好多人问我如何评价 Manus, 我会尝试反向的问对方是什么感受 。
得到一个很有意思的观察 , 大厂人往往会把其归结为过度的营销 , 投资人则关注壁垒是什么 , 商业模式是什么 。
创业者大多会兴奋看到了机会 , 普通会用户会迷茫这是啥 , 媒体人更直接有没有码 。 细思这背后其实都是在看自己 , 大厂人担心丢了尊严 , 用营销解释容易心安 , 投资人是 FOMO, 担心没投错过 , 投了又亏钱 , 创业者是羡慕 , 希望下一个是自己 , 用户最不是这是啥 ,是最客观的评价者 。
媒体人是在想着怎么获取图和流量 , 忙忙碌碌皆是围绕自己 , 只有用户保持着朴素的好奇心 , 这是啥 ?
所以最后一页我想说的是什么 ? 第一 ,在过去两年多的时间里面 ,在 AI 这个我叫黑暗森林年代 ,但凡有人踏出一步踏对了 , 市场总会给你比你预期多的多的多的正反馈 。
这件事情已经被无数次证明了 。 我们要感谢 Manus 在 25 年出的爆火 ,25 年的 AI 行业会越发的具有挑战与诸君共勉 。
感谢收听这期播客 , 我的 PPT 在声诺里 ,有需要可以下载 , 感谢感谢 。